OpenAI GPT-5.2

Introduction
OpenAI have released GPT-5.2 on Thursday. The release in accompanied by an Update document to the GPT-5 System Card. All GPT-5.2 models now have a native knowledge cut-off of August 31 2025 specified. The context window size is 128K for gpt-5.2-chat and 400K for the reasoners (gpt-5.2-thinking and gpt-5.2-pro). The per-token pricing is the same for both gpt-5.2-chat and gpt-5.2-thinking), but is more expensive that 5.1 - Simon Willison writes:
Pricing wise 5.2 is a rare increase—it’s 1.4x the cost of GPT 5.1, at $1.75/million input and $14/million output. GPT-5.2 Pro is $21.00/million input and a hefty $168.00/million output, putting it up there with their previous most expensive models o1 Pro and GPT-4.5.
Long context use
LLMs have traditionally displayed uneven attention spans, with accuracy either being U-formed or drastically dropping off. OpenAI claim to have starkly improved on this versus GPT-5.1:

Benchmarks and pricing
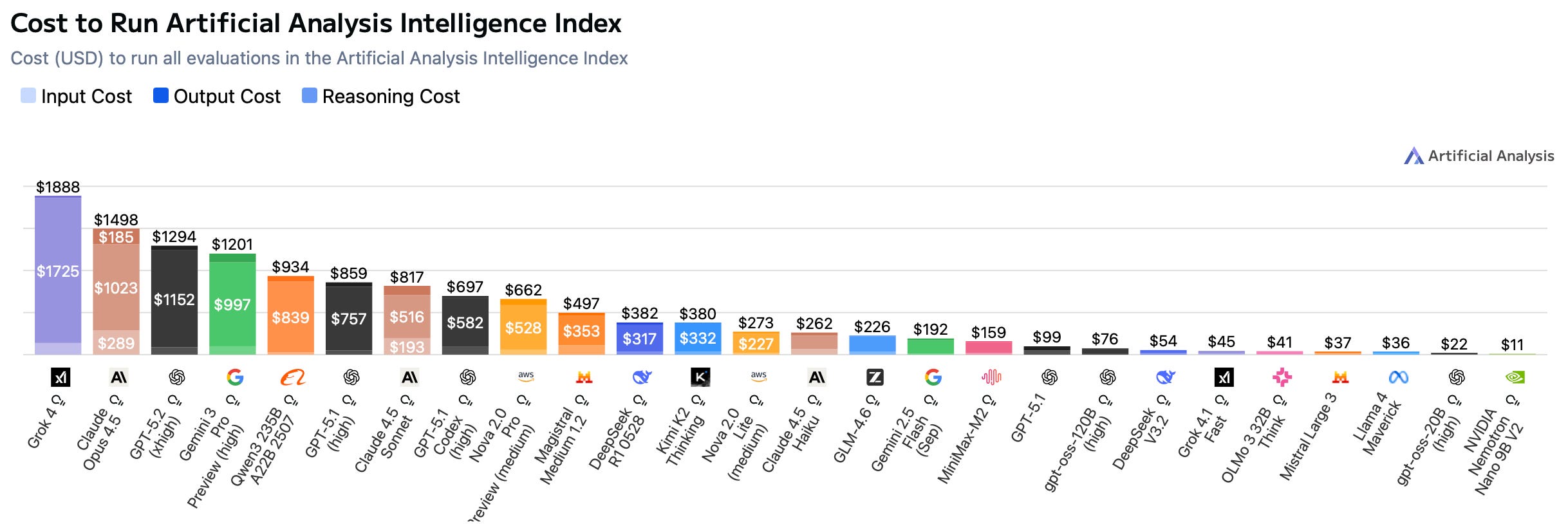
Benchmark results are generally favorable, with GPT-5.2 “xhigh” gaining +3 points over GPT-5.1 high on the amalgamation Artificial Analysis Intelligence Index, now matching Gemini 3 Pro. The actual cost to run their analysis is lower for GPT-5.2 xhigh than Grok 4 or Claude 4.5 Opus, but 7,7% more expensive than Gemini 3 Pro and 50% more expensive than GPT-5.1 high.
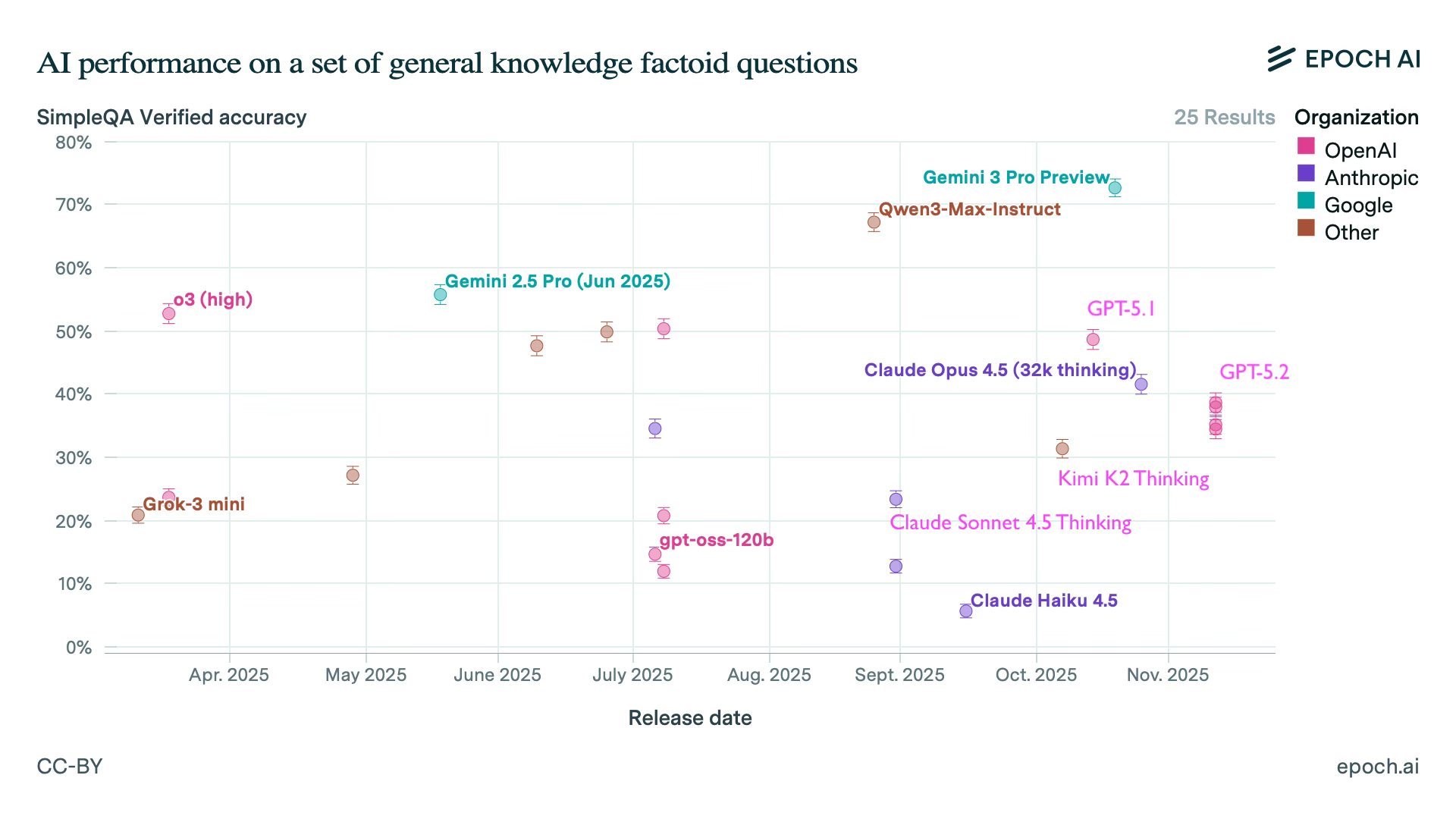
Noteworthy, GPT-5.2 underperforms o3, GPT-5 and GPT-5.1, as well as Claude Opus 4.5 Thinking, Gemini 3 Pro, and Qwen 3 Max on SimpleQA Verified. On the other hand, it outperforms Claude Sonnet 4.5 Thinking and is on par with Claude Opus 4.1.
Also, GPT-5.2 grossly underperforms on (the controversial) SimpleBench, coming in 17th (GPT-5.2 High) and 8th (GPT-5.2 Pro).
GPT-5.2 is GPT-OSS-shaped (insane reasoning, less world knowledge)
Vision
OpenAI claim that GPT-5.2 is the best vision model they have ever released, but Jerry Liu of LlamaIndex indicates that this is just because of the agentic work happening in ChatGPT:
GPT-5.2 Thinking is really good at parsing charts
[…] The native visual understanding capability of GPT-5.2 is not amazing […] But both GPT-5.2 Thinking and Pro make up for that by spending a *ton* on reasoning tokens in order to break down the chart image and plot every point.
I would love to see current Vision - and also Video Understanding - benchmark results.
AI Safety
Apollo Research were again part of the safety evaluations:
gpt-5.2-thinking occasionally engages in deceptive behaviors such as falsifying data, feigning task completion, or strategically underperforming when given an explicit in-context goal, but it shows low rates of covert subversion against developers and does not engage in sabotage or self-preservation behaviors in these settings […] gpt-5.2-thinking may exhibit higher awareness of being evaluated than some prior OpenAI models […]
Their findings are framed as “broadly comparable to other recent frontier models”, concluding that it “is unlikely to be capable of causing catastrophic harm via scheming”.
Sub-model confusion
The GPT-5.2 release again blurs the line between what exists in ChatGPT and what is exposed in the API.
In the ChatGPT UI we get three options: “GPT-5.2 Instant”, “GPT-5.2 Thinking”, and “GPT-5.2 Pro”. On the API side, OpenAI offer three closely related models: `gpt-5.2-chat-latest`, `gpt-5.2`, and `gpt-5.2-pro`. The implied mapping is fairly clear: Instant → `gpt-5.2-chat-latest`, Thinking → `gpt-5.2`, Pro → `gpt-5.2-pro`.
The confusion starts with how this is described. Simon Willison’s initial write-up repeated a line from the docs that called `gpt-5.2-chat-latest` “the model used by ChatGPT”. I replied on X pointing out that this is imprecise: in the ChatGPT product, `gpt-5.2-chat-latest` corresponds to the non-reasoning “Instant” entry in the model picker, not to “ChatGPT” in general. Simon then started a separate thread about the underlying model layout.
In that second thread Simon wondered whether “Instant” and “Thinking” are in fact the same base model with different `reasoning.effort` settings applied, or whether Thinking really maps to the separate `gpt-5.2` reasoning model. OpenAI now expose `reasoning.effort` as a parameter with several levels, and ChatGPT may even use some internal setting for it (style control comes to mind), but the public documentation stops short of spelling out if/how the three UX modes are wired to the three API models plus that parameter.
My current reading is this: treat `gpt-5.2-chat-latest`, `gpt-5.2`, and `gpt-5.2-pro` as distinct endpoints with different context windows and behaviour. Do not assume you can reconstruct “GPT-5.2 Thinking” by taking `gpt-5.2` or “GPT-5.2 Instant” by taking “gpt-5.2-chat-latest”.